
Benchmark uWSGI vs gunicorn for async workers
All of the WSGI benchmarks I found were pretty outdated or didn't include async results, so I decided to do some benchmarking myself.
I know there's other options for running python WSGI applications, but I settled on just 2: gunicorn, which has the advantage of being pure-python and uWSGI, which has the advantage of being pure-C.
I ran these tests on a m1.large Amazon AWS EC2 instance using the latest ubuntu 64-bit AMI at the time, ami-097ace60. /proc/cpuinfo reported the CPU as 2 cores of Xeon E5507 @ 2.27 GHz. The only system setting I had to tweak was net.ipv4.tcp_tw_recycle as there were a lot of connections in TIME_WAIT state which resulted in nginx dropping connections with the following error appearing in the logs:
[crit] 12428#0: *1638091 connect() to 127.0.0.1:8000 failed (99: Cannot assign requested address) while connecting to upstream
Here's the command needed to set the value on ubuntu:
sudo sysctl -w net.ipv4.tcp_tw_recycle=1
And to get everything needed for the test installed, I used:
sudo apt-get install nginx libevent-dev python-pip build-essential python-dev
sudo pip install requests==0.14.0 gunicorn==0.14.6 uwsgi==1.2.6 gevent==0.13.8 eventlet==0.9.17
I did not actually touch anything in the nginx config, as that wasn't the point of this benchmark. Seems that it came pre-configured with 4 workers on ubuntu. Only thing I had to change was to route requests to gunicorn:
location / {
proxy_pass http://127.0.0.1:8000;
}
and to uwsgi:
location / {
uwsgi_pass 127.0.0.1:8001;
}
The actual benchmarking was done from a separate machine on the same local network using ApacheBench for a fixed number of requests and variable concurrency value (number of threads ab uses for the benchmark). To help automate the process I used this simple python script:
import subprocess
for c in [1, 5, 20, 40, 60, 80, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300]:
subprocess.call(["/usr/bin/ab", "-n", "10000", "-c", "%s" % (c), "http://10.1.1.1/"])
First, I ran a test on a simple hello-world application kindly borrowed from Nicholas Piël:
def application(environ, start_response):
status = '200 OK'
output = 'Pong!'
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
I ran separate tests using 2 and 4 worker processes for both gunicorn and uWSGI. Having just 1 worker was too low and 6 was too high and produced worse results than 2 and 4 workers in all cases. I also tried using the multiple threads per process in uWSGI, but that produced worse results as well.
Here are the results:
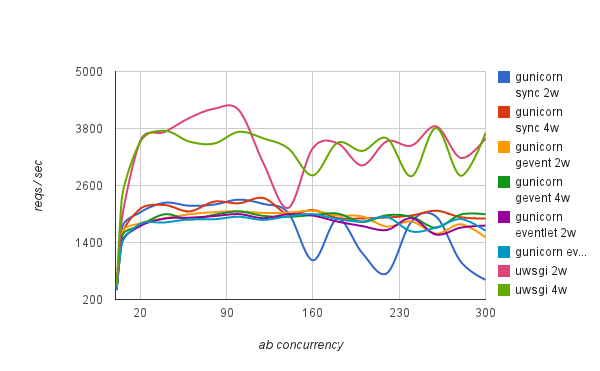
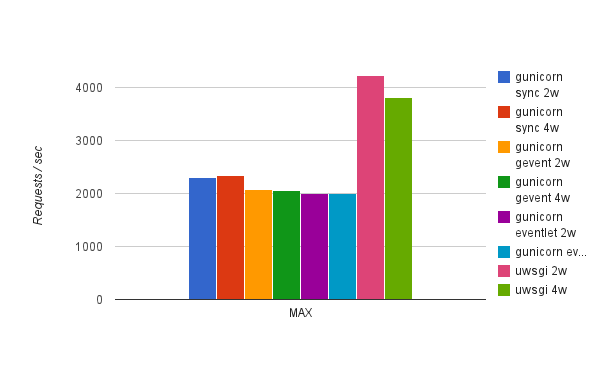
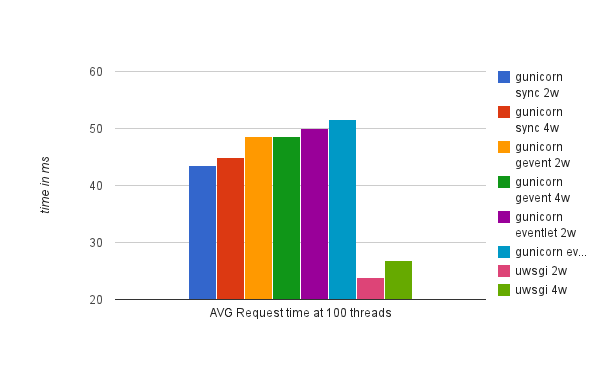
As you can see uWSGI has a clear advantage over gunicorn here being able to handle almost twice the number of requests per second for this simple example. Also, our applications saw worse performance in gunicorn using gevent and eventlet asynchronous workers, which makes sense as it doesn't have any of the behaviors typically present in applications that require asynchronous workers (e.g. streaming and long-polling) as described here. This is also why I didn't even try uWSGI async options for this test.
Now, on to an async test. For this I used a simple application, the sole purpose of which is to send an outside HTTP request and display the output.
import requests
def application(environ, start_response):
status = '200 OK'
r = requests.get('http://10.1.1.2')
output = r.content
response_headers = [('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
Obviously, this application is going to be heavily dependent on the HTTP response from the server that it queries so we can't compare results to the previous ones.
Below are the results of running this test:
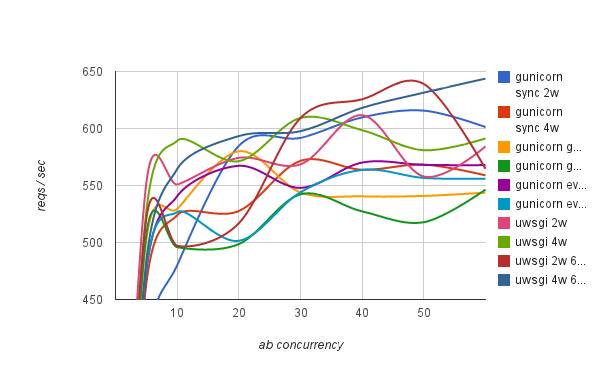
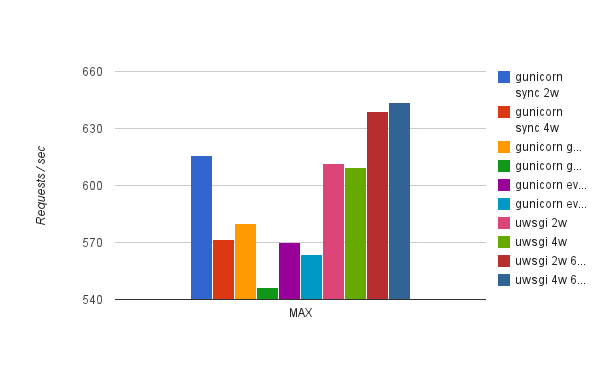
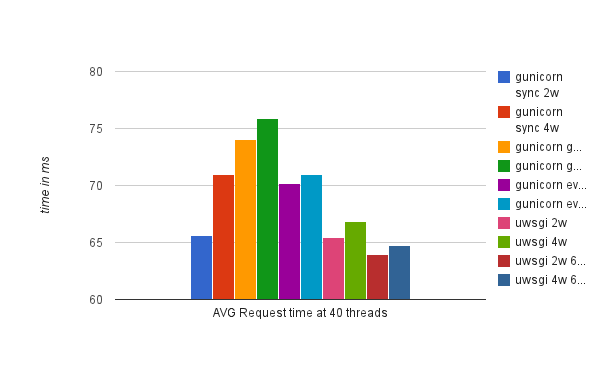
As you can see, there's no clear winner here with uWSGI async workers having a slight edge over their sync counterparts. For gunicorn, sync workers actually had the best results with gevent and eventlet being left behind. Granted, it's not the best example of an async application, but uwsgi did show 3 "Async switches" per request. This particular example did not benefit much from async support of both servers. I suspect it's because the local HTTP request executed too fast to benefit from async workers. So, next I ran the same test, but making an outside HTTP request instead. Results are below:
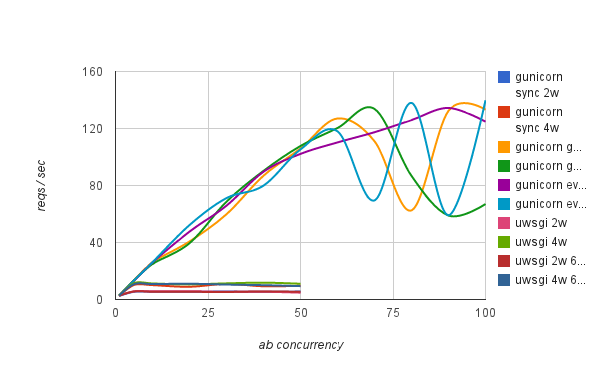
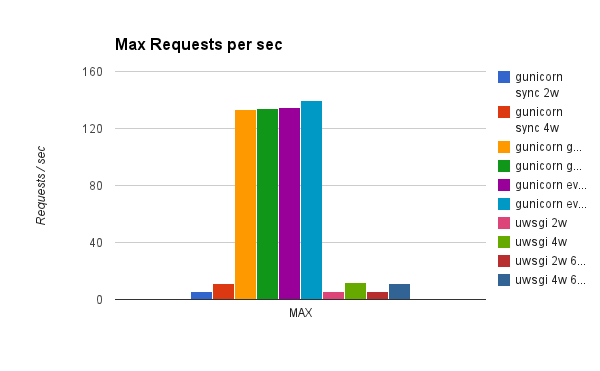
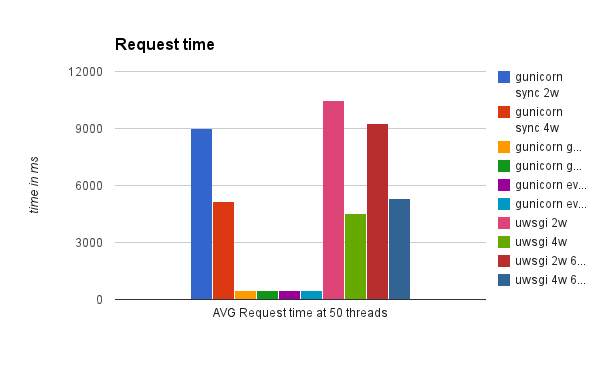
Now we see that gunicorn with gevent and eventlet are clear winners. uWSGI with async workers performed just like in synchronous mode, which was surprising. Looking further into documentation it seems that you have to specifically code your application to uWSGI async mode and call uWSGI-specific methods like uwsgi.wait_fd_read(fd, timeout). So, for a future benchmark I'll look into the possibility of modifying requests module to work specifically with uWSGI. For now as an off-the-shelf solution, gunicorn with gevent/eventlet performs the best for this application.
One other thing I tried was wrapping requests.get() call into a gevent.spawn() which can be easily done with grequests. This didn't actually help gunicorn and made uWSGI fail under heavy load with the following error:
[err] evmap.c:401: Assertion ctx failed in evmap_io_active
For a future test, uWSGI seems to be working on their own gevent support - http://projects.unbit.it/uwsgi/wiki/Gevent - which currently requires manually recompiling uWSGI, which I didn't feel like doing just yet.
Posted Wed 12 September 2012 by Ivan Dyedov in Python (Python, Ubuntu, WSGI, uWSGI, gunicorn, benchmark, nginx, gevent, eventlet)